The models used in weather and climate predictions are primarily based on laws of physics that are fairly well understood at the mathematical level.
However, once you incorporate the huge range of scales necessary to predict a localised, individual weather event, or the statistical effects on weather events with a changing climate, things get very complicated.
There are three main computational steps involved to forecast the weather. First, observation processing, which collects observational data and performs pre-processing on that data.
Second, we have optimisation methods for deriving the initial conditions for forecasts. Dr Peter Bauer, deputy director of research at the European Centre for Medium-Range Weather Forecasts, explained: ‘They aim at finding the optimum value from having a first guess what that value might be (i.e. a forecast) and observations of that value.’
Both first guess and observations are not perfect, and the optimisation algorithm is taking these errors into account. Ensemble methods are used to actually characterise these errors. ‘For weather forecasts it is not a single value that needs to be found but the probabilities of optimal states for the entire atmosphere at a certain point in time. The dimension of this is 6.5 million grid points x 137 levels x 10 variables right now, and is therefore a very big problem that requires substantial computing resources,’ Bauer added.
Third, model forecasts, which are based on two families of methods: resolved processes (which act on scales that are explicitly resolved by the model grid) and unresolved processes (which act on scales smaller than the grid). Bauer explained: ‘Examples are clouds, convection or turbulence. The methods to calculate their impact on the resolved scale are called parameterisations because they involve simplified formulations of the physics.’
Climate prediction focuses on the last step because when you predict the evolution of climate for time scales beyond decades, the forecasts are not dependent on the initial conditions anymore.
Earth system modelling
Earth system modelling involves the integration of several numerical models resolving the climate system that are based on equations, each one simulating one of the different Earth system components, such as the atmosphere, ocean, sea-ice, land surface, vegetation, chemistry, and so on.
Dr Mario Acosta, leader of the performance team for the Computational Earth Sciences group at the Barcelona Supercomputing Center (BSC), explained: ‘For example, in climate problems we mainly use the operational global Integrated Forecast System (IFS) for the atmosphere component, and the Nucleus for European Modelling of the Ocean (NEMO) for the ocean and sea-ice components.’
Miguel Castrillo, leader of the Models and Workflow team for the Computational Earth Sciences group at the BSC, added: ‘Complexity comes when all these components, which solve the nonlinear equations that describe the movement of fluids in different global grids (the Navier Stokes equations), are executed at higher resolutions than what is usually performed in most institutions, and exchange information and interact in a synchronised way.’
The BSC uses its Marenostrum supercomputer to tackle such models. Acosta said: ‘The problems we deal with have a vital need for high performance computing with sustained computing power of the order of 1 Pflop/s or more. To maximise these computing resources, the Earth Science department is working very hard in the improvement of the energy efficiency of computational models.’
‘This is done by using the BSC Performance Tools suite, to profile the model executions and optimise those parts of the code that represent a bottleneck for the parallel execution (this includes algorithms, memory management or I/O),’ Castrillo added.
A substantial effort to optimise the coupling between the different model components of the European community model used for climate research has shown that important reductions in the time to solution can be achieved by analysing the code behaviour with these performance tools. Professor Francisco Doblas-Reyes, head of the Earth Sciences Department from the BSC, said: ‘This work is likely to have a large impact in the ambitious experiments to inform climate change negotiations planned with this model across Europe.’
‘An innovative framework for the verification of climate predictions has been created that considers the observational uncertainty from a completely new perspective. This work includes an approach to deal with the observational uncertainty propagation in the analytics carried out to assess model performance,’ Doblas-Reyes added.
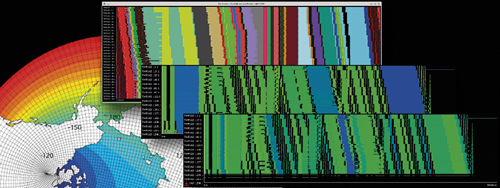
The image 'earth-model-performance' was prepared to illustrate the section on Earth model performance analysis in the BSC website (It's obtained using a combination of outputs from the Ocean Global Circulation Model, NEMO, and a serial efficiency graph) (Credit: BSC)
Modelling uncertainty
Researchers at the Predictability Group at the University of Oxford are tackling the uncertainty of the quantitative predictions made during weather and climate modelling.
Understanding this uncertainty is vital for leaders to make informed decisions as to whether, for example, to evacuate a city based on the likelihood of a hurricane hitting that centre of population. Professor Tim Palmer, Royal Society research professor in the Department of Physics at the University of Oxford, explained: ‘A lot of physics is not resolved using such models. For example, individual clouds or turbulence in the lower kilometre of the atmosphere are usually not resolved and we need simplified formulae to come in.
‘However, the effects of the variation in these unresolved processes can affect the state of the system in the large scale. Such a deterministic approach dampens out these processes,’ Palmer added.
A different approach is to introduce a stochastic parameterisation, which introduces a certain level of variability into the model. Palmer said: ‘If we have a nonlinear system and we add some random noise, we can change the state of the system. This improves the accuracy of the model without the computational resources needing improvement.’
This stochastic parameterisation approach has practical consequences. In a computational weather and climate model, you may need to include tens or hundreds of millions of variables. This is computationally incredibly expensive and today’s supercomputers are constrained by their energy and power consumption – and by how many bits they can essentially move around when running a model.
This is a universal problem within weather and climate modelling that the supercomputer manufacturers must address for this sector, as Dr Michael Farrar, director of the Environmental Modeling Center (EMC) at the National Centers for Environmental Prediction (NCEP) and the National Oceanic Atmospheric Administration (NOAA), part of the US department of commerce, explained: ‘The processing power has long been the focus – but this is no longer the biggest challenge for running high-resolution models on massively parallel processing (MPP) computer systems. It is the communication between processors which is slowing us down and what is really pulling us back.’
This input/output issue could be addressed by lowering the precision of specific variables, as Palmer explained: ‘The default is to represent a variable with 64-bits of precision. This means we have billions of bits in a machine that are being communicated around. But how many of these bits represent real information?’
Some variables could be ramped down to 32-, 16- or even 8-bits of precision to reduce the power consumption of the supercomputers running these models. Palmer said: ‘We gain more accuracy with less precision. We want to reduce precision to remove what is not necessary but redeploy the computational resources to increase the accuracy of the model.’
If a 64-bit precision is replaced with a 32-bit precision then this will degrade the forecast, but it is such a small effect compared to the uncertainty in the model and the initial conditions, that the forecast is not adversely affected.
A new paper from the team recently demonstrated that 32-bit precision is sufficient for almost all parts of a weather forecast model to generate accurate simulations when compared to a 64-bit precision - but with power consumption savings of roughly 40 per cent. Work will continue to see how much further this precision, and consequently the power consumption, could be reduced.
Atmospheric grids
The NOAA in the US is currently developing a state-of-the-art global weather forecasting model to replace the US’s current Global Forecast System (GFS).
The new offering (which will continue to be called the GFS) is currently under development with a prototype planned for 2018, and an operational version in 2019. Both the existing and the next-generation GFS run in the background of the NOAA’s diverse range of weather and climate models to improve all of the association’s forecast areas.

NOAA's new supercomputers - called Luna and Surge - are located at computing centres in Reston, Virginia and Orlando, Florida. They are now running at 2.89 petaflops each for a new total of 5.78 petaflops of operational computing capacity, up from 776 teraflops of processing power before the upgrade. The increased supercomputing strength allowed NOAA to roll out a series operational model upgrades in 2016-17.
The current GFS runs a spectral model, which breaks down the atmosphere’s behaviour into waves but (as resolutions increase) it is reaching its natural limit. Farrar said: ‘This was a very elegant solution but as we get to higher resolutions then it becomes less efficient computationally. So, as all our models push the resolution, we are moving away from a spectral model and to a grid point model.’
The grid point model breaks down either the entire globe or a regional area into a grid system where forecast points are laid out in the grid area they cover. The grid points are the distances between the centres of these grids.
As the number of grid points increases, so does the resulting detail in the forecast – and the need for more computing power. The NOAA’s Geophysical Fluid Dynamics Laboratory is adapting and improving their dynamic core, called the Finite-Volume on a Cubed Sphere (FV3), from its legacy in climate models to bring a new level of accuracy and numerical efficiency to the grid point model’s representation of atmospheric processes as a weather forecast model.
The FV3 core means the model can provide localised forecasts for several weather events simultaneously – and generate a global forecast every six hours.
The grid point model also aims to better model forecasts of hurricane track and intensity, and extend weather forecasting through to 14 days – or even extend it to three to four weeks for extreme events.
Better resolution
The Australian Government’s Bureau of Meteorology uses computational models similar to those above to simulate the atmosphere, ocean, land surface and sea ice to predict and warn of severe weather and climate events. These models run on some of the most powerful supercomputers in Australia, including the Bureau’s new Cray XC40 machine in Melbourne and, for research, the Fujitsu and Lenovo machines at National Computing Infrastructure (NCI) at the Australian National University in Canberra.
The atmospheric model is developed as part of an international partnership lead by the UK Met Office and several agencies in other countries including Australia. The models are developed in partnership with the Bureau of Meteorology, CSIRO and the university-based ARC Centre of Excellence for Climate System Science, to form a coordinated set of models known as the Australian Community Climate and Earth System Simulator (ACCESS).
There have been several significant developments over the past few years. First, the installation of the Bureau’s powerful new Cray XC40 computer allows for models at significantly higher resolution than before. Dr Tony Hirst, research program leader of Earth System Modelling at the Australian Government Bureau of Meteorology, said: ‘For example, the new global atmospheric model that we are preparing will be run at 12km resolution, double that of the present 25km global model.’
Second, the Bureau has developed the capability to run the atmospheric forecast model many times for each forecast period, each run starting with slightly different initial conditions, to create an ‘ensemble’ of forecast runs. Hirst said: ‘This is important to assess the probability of weather systems developing in certain ways, as, for example, slight errors in the model’s initial conditions resulting from sparse observations may sometimes cause weather systems to develop in quite different ways.
‘As an example, it is especially important to assess the range of probabilities of strength and position of coastal crossing for tropical cyclones, as this is critical to the Bureau’s advice to emergency services. For this purpose, the Bureau has developed a specialised tropical cyclone forecast model, which is run multiple times a day when there is a tropical cyclone present to help gauge the ranges of uncertainty,’ Hirst added.
One interesting prediction from the Bureau’s seasonal prediction model, when run further out to three years simulation, suggests that there is predictability of El Nino and La Nina (the phenomenon where much of the tropical Pacific Ocean is unusually warm or unusually cool, with increased chance of drought or flood over Australia, respectively) for at least two years in advance. However, this work is still in an exploratory stage, according to Hirst.
SPICE of life
The UK Met Office recently installed a new HPC system to improve weather and climate data analysis. The Scientific Processing and Intensive Compute Environment (SPICE) platform is a file storage solution that lets scientists combine data from both current simulations and their huge archive of historic data to build more accurate models.
Laura Shepard, senior director of product marketing at DataDirect Networks (DDN), said: ‘Previously, Met Office researchers used relatively siloed systems that required users to manually seek out available resource across the estate on which to run analysis work. With the new cluster and DDN storage activities that used to take several days – like comparing hundreds of thousands of historic weather observations with their current-day counterparts – now run in several hours.’
Bright Computing was also selected to help with the project as its solutions can be administered from a single point of control. Lee Carter, vice president Worldwide Alliances at Bright Computing, said: ‘With the combined solution of compute, OpenStack, and storage, the Met Office can scale SPICE storage predictably while delivering high-throughput performance to handle simultaneous data reads/writes.’
Using the SGI system, the Met Office’s researchers can spin up virtual machines easily and operate their own private virtual environment with full control and direct access to their local network. In addition, they can easily increase the capacity of the virtual environment merely by adding more servers to the OpenStack environments.
‘Scientists using SPICE have already noted significant performance advantages over previous systems, enabling far quicker analysis to support ongoing research. Massive volumes of data are now analysed in several hours, rather than days. The improvements support and enhance ongoing development of meteorological and climate change research,’ Carter added.
The human touch
While complex algorithms and powerful supercomputing facilities are vital, the portability of code is also an important commodity in today’s weather and climate modelling.
The Joint Effort for Data assimilation Integration (JEDI) is one multi-agency initiative in the US addressing this challenge and aims to develop a unified community data assimilation system where the initial conditions for the forecast model are estimated from meteorological observations.
Unlike other such systems, the JEDI approach will be modular, which improves the flexibility, readability, maintenance, optimisation and testing of the code. The EMC is one of the central partners for JEDI, and Farrar said: ‘We are trying to lower the barriers between coding and science so our scientists can spend more time focussing on the science, rather than rewriting or maintaining code. This allows us to be more efficient and develop a better scientific model.’
The need to free scientists to do science is a global requirement. For example, STFC (Science and Technology Facilities Council) is collaborating with the Met Office on its next-gen atmosphere model. STFC is developing a code generation system, called PSyclone, to help a user parallelise and optimise the code for a particular architecture.
This automation has enabled the UK Met Office’s prototype dynamical core to go from serial execution to running on more than 250,000 cores with no change to the scientific code base. STFC is now exploring opportunities to make PSyclone available for other science and technology industries.
Luke Mason, who leads the High Performance Software Engineering Group at STFC, said: ‘PSyclone is a powerful tool that facilitates scientists and HPC experts collaborating to combine cutting edge science with the latest in HPC capabilities. In addition to our work with the Met Office we are seeking to extend PSyclone’s functionality to benefit a broad range of science and engineering disciplines.’
So, whatever the weather, the forecast for supercomputing is good. Optimisation tools and efficiencies are improving to free scientists to come up with increasingly innovative modelling and simulation techniques.
