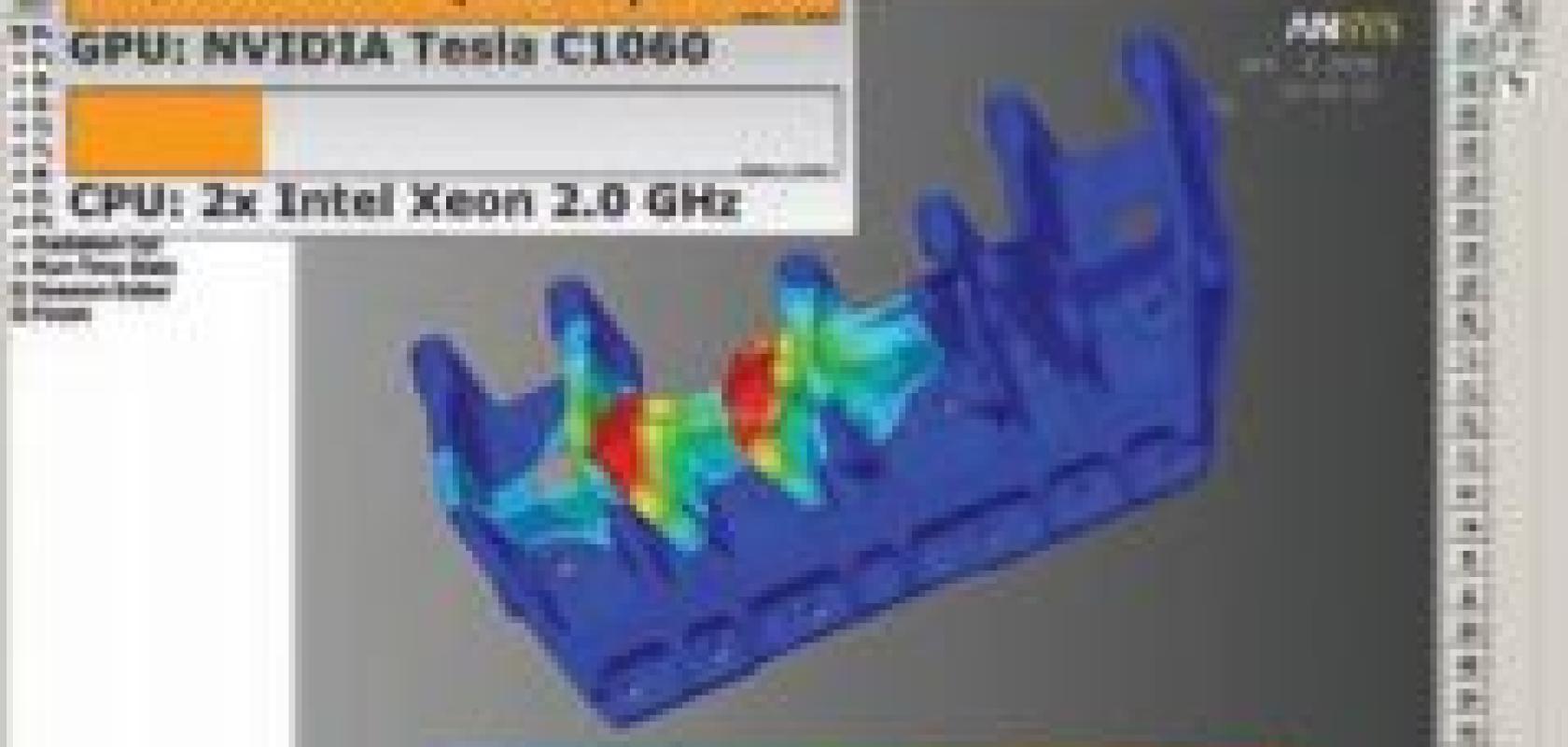
Although we’re excited about the power of dual- and quad-core CPUs, consider the potential of an integrated circuit with many hundreds of cores – and these are already in your desktop or laptop PC in the form of a GPU, intended to accelerate graphics processing. In addition, board-level GPU products are becoming available as are preconfigured ‘personal supercomputers’.
These typically use GPUs from Nvidia and AMD, while Intel has announced its intention to join in the action in a different way. The biggest obstacle for the average end user has been getting software that runs on such devices, but that situation is changing. Leading ISVs (independent software vendors) have either modified their software to run on GPUs or will have such software shortly. The benefits can be astounding: depending on the actual algorithms being run, a GPU can increase performance by an average of 10x and sometimes by a factor of 100x or more.
Fat vs lean processors
To understand how these gains are possible, you must understand the architectural differences between the two classes of processor. Sumit Gupta, senior product manager for Nvidia’s Tesla GPU Computing Group, explains that traditional CPUs are ‘fat’ in that they have large caches and a rich instruction set and thus are suitable for unpredictable tasks. In contrast, GPUs have hundreds of ‘lean’ processors with reduced instruction sets, lots of small distributed memories, but are designed for predictable, compute-intensive tasks where the algorithms remain the same and only the inputs change. The gains are achieved by taking an algorithm that requires massively parallel computations and splitting them up among the GPU’s cores. And while this power is limited to only certain types of applications, these are the ones that scientists and engineers frequently use.


Comparison of LU decomposition, a common matrix operation, performed with and without GPU acceleration (courtesy of the MAGMA project at the University of Tennessee, Knoxville, and the University of California, Berkeley).
As with any technologies, there are downsides. A limitation of GPUs is the requirement for a high level of parallelism in the application, while another is power consumption: GPU boards often consume much more than 100W. GPUs also place greater constraints on programmers than do CPUs. For instance, to avoid significant performance degradation it is necessary to avoid conditionals inside kernels. Finally, GPUs suffer from latency in CPU-GPU communication. Unless the amount of processing done on the GPU is great enough, it might be faster to simply perform calculations on the CPU, but GPU developers are working to make communications and computations overlap without much effort by the programmer.
Boards for different target markets
Not only are GPUs supplied with many PCs, others interested in adding this capability can purchase board-level and box products with GPUs. Nvidia offers several families of products, but they are all based on the same basic chip, the T10-Series GPU. It features 240 cores for 1 Tflops of single-precision (SP) or 78 Gflops of IEEE-compliant doubleprecision (DP) performance – an important addition with this chip because DP is vital in many areas of scientific computing.
Its products are branded differently depending on the target market: GeForce chips and boards are found in consumer products such as notebook and desktop PCs for gaming and video processing; the Quadro family is targeted at professional visualisation and graphics; finally and most recent are Tesla boards, intended for a cluster or workstation for accelerating numerical tasks. As noted, all the families use the same 10-Series GPU, but board configurations differ in their amount of memory. Tesla boards, for instance, have no connectors for displays and work only in combination with a CPU to handle parallel tasks.
Tesla numeric accelerator products come in two forms: the Tesla S1070 is a 1U server system with four T10 GPUs; next, the Tesla C1060 is a dual-slot PCI Express 2.0 board with one T10 GPU. Further, more than a dozen companies are integrating these board-level products into ‘personal supercomputers’.

The Tesla T10 chip from Nvidia provides 240 processors with double-precision floating-point capabilities in the GPU.
In an interesting announcement, the first GPU cluster to break into the Top 500 list of supercomputers is the TSUBAME supercomputer from the Tokyo Institute of Technology. It uses 170 S1070s to deliver nearly 170 Tflops of peak SP performance as well as 77.48 Tflops of measured Linpack performance.
AMD tunes GPU for numerics
While Nvidia has market momentum in general-purpose GPUs, AMD has been intensifying its efforts in this arena, based primarily on the technology it got with the acquisition of graphics-chip maker ATI in 2006. AMD, however, has only recently started addressing scientific/engineering markets even though it was the first to market with a double-precision GPU board. That company’s boards consist of the Radeon line for consumer graphics products, the FirePro line for professional graphics and workstations, and most recently the FireStream for computer-specific applications.
Scientists will be most interested in the FireStream family, which is based on the RV770 chip architecture with 800 stream processors. Here two boards are available. The single-slot FireStream 9250 offers 1 Tflops SP/200 Gflops DP performance, and slated for availability this quarter is the FireStream 9270, a 2-slot board that increases the GPU’s clock speed to achieve 1.2 Tflops SP/240 Gflops DP performance.
AMD is starting to enter into the box market and has demonstrated its boards working the CA8000 from Aprius Inc, a 4U box that holds eight FireStream 9270s. It is also working with HP’s HPC Accelerator Program to ensure that ATI Stream technologies are validated for use on a selection of HP ProLiant servers.
Software catching up to hardware
All this hardware does no good without tools that help programmers write code to run on GPUs. Indeed, software tools are the Achilles heel of accelerators, comments Ryan Schneider, CTO at Acceleware, who adds that this is why other accelerator approaches such as FPGAs have had trouble getting traction. As for GPUs, he says that most ISVs have enough trouble squeezing performance out of a quad-core CPU without adding a different beast into the mix. However, recent tools from GPU vendors such as Cuda have gone a long way in solving this challenge.
Indeed, Cuda (originally Compute Unified Device Architecture) is one of the driving forces behind Nvidia’s GPUs. This parallel-computing GPU/software architecture can be programmed using standard languages. Free Cuda software tools include standard C for the development of parallel applications, while Fortran and Java wrappers are also available.
Numeric libraries consist of Cufft for fast Fourier transforms and Cublas (Compute Unified Basic Linear Algebra Subprograms), and also free is a Cuda driver for fast data transfers between the CPU and GPU.
While using the Cuda APIs alone can result in a performance boost, to get spectacular improvements such as a 100x acceleration, users must know that hardware very well, specifically memory issues. So says David Yip, new technology business manager for HPC integrator OCF. The GPU has a very small memory, but the datasets being worked on are very large with some servers holding 32G bytes or more. It’s important to determine which data goes on the GPU, when, and how to move it.
For development tools, AMD prefers the open systems approach. Free tools start with CAL, which gives low-level access to the hardware similar to assembly programming. Next is Brook+, based on an open-source project from Stanford University, and it is a C-like environment where programmers create a back end that talks to CAL.

Nvidia’s T10 CPU comes packaged as a PCI Express board in the Tesla C1060 and as a 1U server product, the Tesla S1070.
The new ATI Stream SDK 1.3 includes a re-architected version of Brook+ that enhances runtime performance. In addition, users can download the GPU-compatible ACML (AMD Core Math Libraries). The company also offers a free download of the ATI Catalyst driver that unlocks ATI Stream acceleration capabilities already built into FireStream boards plus ATI Radeon graphics cards.
One thing that will open up the market, says AMD’s director of stream computing, Patti Harrell, is an industry-standard API, and she sees the answer in OpenCL, which is a framework for writing programs that execute across heterogeneous platforms consisting of CPUs, GPUs and other processors.
OpenCL was initially conceived by Apple, which submitted an initial proposal to the Khronos Group, which in turn is a member-funded industry consortium focused on the creation of open standard, royalty-free APIs. Nvidia has also pledged support for Open-CL, in fact the standard was developed on Nvidia GPUs so it’s clear that it will have broad industry support. OpenCL Ver 1.0 was approved for public release at the end of last year, and users can look for a developer release in the first half of this year.

The AMD FireStream 9250 (bottom right) plugged into an HP 385 server.
Tools for programmers
Meanwhile, programmers doing their own coding can take advantage of new tools that seem to be sprouting up like mushrooms. The Portland Group this quarter expects to add support for Nvidia GPU accelerators to its PGF95 Fortran and PGCC ANSI C99 compilers and has also entered into an agreement with AMD to develop compiler technology for FireStream boards – but this technology preview supports only integer and single precision floating-point operations. The argument for using a GPU isn’t nearly so convincing with GPU DP performance as it is today, although several researchers, such as Jack Dongarra at the University of Tennessee, are working on mixed-precision and iterative solvers that use SP for most of their computation and only use DP to converge on the results. Technically, supporting DP is not costly, and the Portland Group plans to revisit this decision based on performance and user feedback. For other GPU programming tools, consider the Magma project, led by the linear algebra research groups at the University of Tennessee, UC Berkeley and UC Denver, which aims to develop a library similar to Lapack, but for heterogeneous/hybrid architectures, starting with the current multicore+GPU systems. In addition, GPU VSIPL from the Georgia Tech Research Institute is an implementation of the VSIPL (Vector Signal Image Processing Library) Core Lite Profile that targets GPUs that support Cuda. Next is GPULib, a library from Tech-X that executes vectorised maths functions on Nvidia GPUs. It provides bindings for development environments including Matlab and IDL (from ITT Visual Information Solutions).
Developers are also getting assistance in creating Cuda code from firms such as Acceleware. That company writes specialised algorithms and solvers for selected industries, at this time focusing on electromagnetic and antenna design, oil/gas exploration and general matrix solvers with some activity in finances, biomedical and imaging. Acceleware creates libraries – similar to traditional numerics libraries but at a much higher level – that ISVs then integrate into their programs. For instance, explains Schneider, Ansys software makes a call to his libraries to offload the work of a direct solver, and it also provides software that handles the calls and data transfers from the CPU to the GPU.
Besides many pure-play graphics processors, Rapidmind is starting to support Nvidia and AMD GPUs with its software-development environment. Here developers write code in C++ and the RapidMind platform then ‘parallelises’ it across multiple cores. The application is then run on RapidMind’s development platform, which dynamically compiles those sections into a parallelised program object.
Certain industries that rely heavily on proprietary codes, such as oil/gas exploration and the financial industry, have teams of programmers who can take advantage of Cuda. However, the average scientist or engineer simply wants to be able to purchase software that is GPU-enabled. Fortunately, ISVs are starting to see the enormous potential of GPU acceleration of their software and have either issued Cuda versions or are working on them. Wolfram Research has announced that Mathematica 7 is a Cuda-accelerated release of the software scheduled for this spring. Nvidia has developed a Matlab plug-in for 2D FFT calls, and AccelerEyes has created a GPU engine for Matlab-based on Cuda called Jacket (see page 28), which uses a compile on-the-fly system to allow GPU functions to run in Matlab’s interpretive style.
For its LabView software, National Instruments has announced prototype development systems. Ansys has adapted two of its solvers in Ansys Mechanical to run with Cuda. And if these leading software companies are migrating towards Cuda, many more are sure to follow so their software can remain competitive.
An embryonic market
Concerning future trends, consider that Intel announced its Larrabee ‘many-core’ x86 architecture last autumn, but the initial indications are that it is emphasising graphics acceleration. The first product based on Larrabee is expected this year or next.
The established GPU companies aren’t standing still. Nvidia has doubled its floatingpoint performance every 15 to 18 months and expects to stay on that track. AMD’s Harrell feels that with her company’s expertise in both GPUs and multicore CPUs that it can lead in what it feels is the inevitable shift of GPU capabilities into CPUs.
One of the big names in HPC, IBM, is taking a more reserved attitude towards GPUs. Dave Turek, VP of Deep Computing, notes that the company currently has no GPUs in its portfolio. ‘The use of GPUs is very embryonic and we are proceeding at an appropriate pace.’ He believes the industry has entered a period of evaluation that will last between 18 to 24 months and there will be a gradual dissemination into more conventional segments.
GPU clusters will be slow in coming, insists OCF’s David Yip. He notes that as customers move from GPU boards to clusters, they will need to restructure data from ‘coarse grain’ data decomposition to ‘fine grain’ on a GPU to run it on multiple GPUs in cluster nodes. At the moment, he adds, nobody has really come up with a system of managing the data decomposition, and this will slow the adoption of GPU clusters.
A final thing to watch for is the release of Apple’s Mac OS X Ver. 10.6 Snow Leopard, which is expected for release this year. That OS extends support for modern hardware with OpenCL, which Apple says ‘lets any application tap into the vast gigaflops of GPU computing power previously available only to graphics applications’.
