Since the 19th century, scientists and physicians aiming to control infectious diseases have relied on tools for mapping them. The most famous early practitioner of this is doubtless John Snow, who tracked a London cholera epidemic in 1854 to a single contaminated water pump, providing a vital piece of evidence to show the disease to be water-borne.
Several decades later, painstaking house-by-house mapping of smallpox epidemics in London helped Royal Commissioners determine how hospital provision should be structured. These maps, which have been preserved, are an early example of how the science of epidemiology – or the analysis of the distribution and determinants of a disease in a population – can help combat an infectious disease.
They can provide evidence of links between people’s attitudes and behaviour and the spread of disease, as Heidi Larson, an anthropologist working at the London School of Hygiene and Tropical Medicine (LSHTM) – where ‘that’ water pump has pride of place on display – explains. 'Resistance to vaccination against smallpox was as strong then, as the so-called ‘anti-vax’ movement is today. It is even possible to detect patterns of vaccine compliance in the smallpox maps'.
Old methods, new tools
The principal task of epidemiologists studying outbreaks of infectious disease has hardly changed in more than 100 years, in that it involves the painstaking mapping of every case of the disease. However, whereas the tools available to even mid-20th century epidemiologists would have been vaguely recognisable to their Victorian counterparts, the last 30 years have seen dramatic changes. Today’s counterparts of those smallpox mappers rely on a wide variety of powerful algorithms for statistical analysis, genome sequencing and GPS, underpinned by equally powerful, if more mundane, tools for the secure storage and rapid retrieval of vast quantities of data.
Computational molecular epidemiology – as this sub-discipline might be called – is now vitally important whenever a new outbreak of an infectious disease arises. The Ebola virus outbreak in West Africa in 2014-16 was a case in point. 'We were called on to model the transmissibility of the disease in different situations, and to find out whether any of the interventions available were able to reduce it,' says Anne Cori, a statistician and mathematical modeller based at the MRC Centre for Global Infectious Disease Analysis, at Imperial College, London.
'Our work can also be useful to medical staff on the ground, who need to estimate resources – hospital beds, units of drug or vaccine, and trained personnel – that will be needed in each area as the epidemic unfolds,' said Cori. At a higher level, the World Health Organisation and large medical charities use similar information to plan future work.
Several novel and important statistical tools and other programs to analyse epidemiological data were developed during the crisis of the 2014-16 Ebola epidemic. It was only after it ended that scientists and developers were able to pay attention to maintaining and improving their code, so it could be re-used more easily in future similar epidemics.
An open-source approach
Thibaut Jombart, who is now based between LSHTM, the UK Public Health Rapid Support Team and Imperial College, was a member of the WHO’s analysis team during that epidemic, developing the team’s analysis infrastructure using the R programming language.
During a ‘hackathon’ on software for outbreak analysis that he organised in Berkeley, California, in 2017, he and a group of colleagues decided to form a network of like-minded people that could decide on the most important priorities and needs for outbreak analysis tools.
He is now the president, and Cori the methodology coordinator, of the International R Epidemics Consortium (Recon), which was incorporated as an NGO in France in September 2018. 'We chose to focus the network only on R, because it has the largest number of statistical libraries of any open-source programming language', Jombart said. 'We were determined to make all our code completely publicly available free of charge, and we didn’t want to have to reinvent the wheel.' Recon has produced, and maintains, a wide variety of tools for outbreak analysis, including – thanks to a diverse membership including statisticians, field epidemiologists and software developers – extensive documentation and open access training resources.
Members of Recon and others were able to test some of their computational tools during a relatively small and well-contained Ebola epidemic in the Democratic Republic of the Congo (DRC) in 2017. When the disease returned the following year, so did the epidemiologists, with software from Recon informing the response on the ground. This current epidemic is much more serious: by May 2019 the known death toll had passed 1,000 and charities were urging the UN to ramp its response level up to ‘level three’: the highest possible, reserved for the most serious global crises.
This epidemic has, however, provided a second opportunity to test candidate vaccines using a technique called ‘ring vaccination’. This involves vaccinating each contact of each person infected, and each contact of those contacts, to form two ‘rings of vaccination’ around each case. 'Consortia developing Ebola vaccines rely on epidemiologists and mathematical modellers to predict which areas the disease will be most active at a given time, and how many cases there will be, so they can estimate the number of vaccine doses required and get them to the right places', explains Cori.
Clearly, software developed during one epidemic, or even for monitoring one disease, will be of limited benefit unless it can be re-used in many situations. Any code that is developed or even adapted ‘on the fly’ in response to an emergency is highly unlikely to fit these requirements. Adapting such software to make it robust and generic enough for rapid and effective re-use is the role of research software engineers such as Richard Fitzjohn, a senior R developer at Imperial College London.
'My background is in software development, not epidemiology' he explains. 'My work is to make the epidemiologists’ lives easier, so they can focus on research questions without worrying about whether the programs will fall over or how long they take to run. Crucially, this also includes improving the interface, so it is user-friendly enough to be used by scientists who may be inexperienced and are bound to be under stress.' Much of the software his group produces is designed to be used in to endemic, as well as epidemic, situations, and to monitor bacterial, as well as viral, disease.
Epidemiologists studying outbreaks of infectious disease have another powerful tool available to them in genomics. It is less than a quarter-century since the genomes of the first pathogenic bacteria were released, often via publication in the most respected journals and to worldwide acclaim. Now, in contrast, a complete bacterial genome can be sequenced very rapidly using relatively cheap equipment. This data has multiple uses, from clinical decision-making ‘on the ground’ to worldwide surveillance programmes for mapping, and thus combating, the spread of antimicrobial resistance.
Epidemic outbreaks
The Centre for Genomic Pathogen Surveillance, based at both the Wellcome Trust Sanger Institute, near Cambridge, and the Big Data Institute at Oxford University, was set up four to five years ago with the ambitious aim of translating microbial genomics into a public health context. Its director, David Aanensen, also leads research programmes in both institutes, developing computational resources that combine statistical and genomics methods to monitor infectious disease worldwide. 'We cover endemic situations, as well as epidemic outbreaks, and both viral and bacterial diseases', he explains.
This is a massive undertaking, and one that cannot be achieved by one research group – or even two – without a comprehensive, worldwide network of collaborators. The centre and its financial backers, particularly the UK’s National Institute for Health Research, are adding to their number by investing heavily in capacity-building. They have set up a worldwide network of genomics labs in low and middle-income countries including India, the Philippines, Nigeria and Colombia, and are providing bioinformatics support and training.
This has clinical, as well as research applications, as Aanensen explains: ‘Any of the labs in our global network can upload a pathogen genome sequence, and our software will immediately generate two lists of antibiotics: one of those that can be used safely and effectively, and another of those to which resistance has developed or is developing.' All the data generated by the network is kept on open access and can be downloaded and analysed using smartphones, putting such analysis theoretically in reach of almost any hospital worldwide. 'We need to deliver our tools in such a way they can be used by the people who stand to benefit the most: those with the fewest resources', says Aanensen.
Clinicians and researchers can also use epicollect5, a tool developed by centre researchers that is available as a smartphone app, to upload geo-tagged information about infections that has been collected in the field. Stored data typically includes demographic information about the patients, locations, symptoms, pathogens and resistance phenotypes; this, again, is completely open access and can be mapped or downloaded in different formats for further analysis.
This tool was developed to be completely generic, and it is frequently used by businesses, ecologists, citizen scientists and schools, as well as epidemiologists and clinicians. ‘One of its most popular current applications is in marine biology; boat owners and tourists in the Channel Islands use the app to upload photos of dolphins, seals, sharks and other sea fauna, automatically-generated GPS data is added and the records stored in a free-to-access database', adds Aanensen.
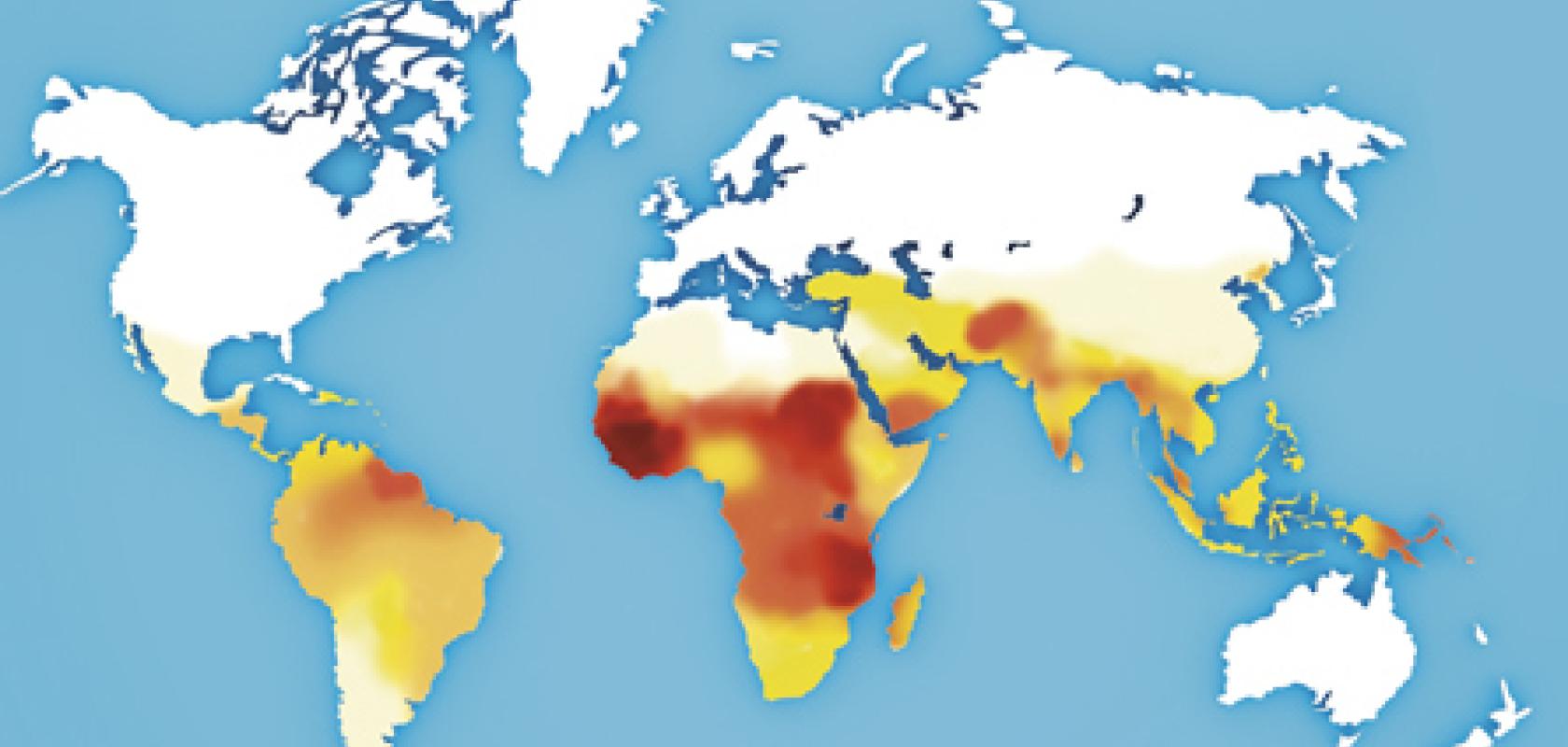
Well over a million people still die of tuberculosis (TB) every year, mainly in low-income countries; it is one of the biggest killers of HIV-infected people worldwide. While drug-susceptible TB can be relatively easily treated with affordable antibiotics, the prognosis is much bleaker for the hundreds of thousands diagnosed with drug-resistant disease.
The World Health Organisation categorises tuberculosis that is resistant to the two mainstay drugs, isoniazid and rifampicin, as multi-drug resistant (MDR). Hundreds of thousands of cases of MDR-TB are diagnosed every year, and, more worryingly still, a growing proportion have extensively drug resistant disease (XDR-TB), which is resistant to two further groups of second-line antibiotics. Almost no treatment is available for tuberculosis classified as totally drug resistant (TDR-TB) which has so far been identified in three countries: India, Iran and Italy.
Determining whether a patient has been infected by the eponymous bacterium Mycobacterium tuberculosis, and if so, whether the strain was drug-resistant, used to be a slow and complex process. This has changed largely thanks to GeneXpert, a desktop machine about the size of a microwave oven that can rapidly amplify DNA in bacteria taken from a patient’s sputum and test for mutations in the gene that determines rifampicin resistance.
‘This machine, which is relatively cheap, will pick up about 95 per cent of all cases of such resistance, enabling healthcare workers to select drugs more likely to be effective in those patients’, says Tim McHugh, professor of medical microbiology at University College London. Whole genome sequencing is also increasingly used in richer countries to identify the extent of drug resistance. 'The complete genome of every Mycobacterium tuberculosis sample isolated from a patient in England [has been] sequenced at one of the Public Health England labs', he adds. 'Detailed bioinformatics analysis of these genomes enables us to track the spread of resistance.'
Fighting malaria
Dominic Kwiatkowski, of both the Sanger Institute and the University of Oxford has been studying another global infectious killer, malaria, since the 1980s when he worked as a paediatrician in West Africa. 'We were trying to find out what made some children much more susceptible to malaria than others, and we thought that genetics might provide useful insights.'
He now heads the genomic epidemiology network MalariaGEN, with a large group of researchers and collaborators studying the interplay between the three genomes that determine malaria susceptibility: the malaria parasite, its vector the Anopheles mosquito, and its human host. MalariaGEN is co-funded by the Wellcome Trust and the Gates Foundation to connect scientists and clinicians working in malaria-endemic countries with state-of-the-art equipment and expertise for analysis of these three genomes.
Kwiatkowski’s team was the first to use genome-wide association techniques to study human resistance to malaria; a computationally challenging problem due to the great genetic diversity of human populations in Africa.
This network, also, is investing in capacity building throughout malaria-endemic regions, training local scientists to monitor the molecular evolution of malaria parasites by establishing in-country sequencing. 'Evolution moves fast, so it is possible to detect evolutionary pressure from patterns of genetic variance and predict resistance before it takes hold, rather like deducing the movement of stars from their red shift', says Kwiatkowski. These predictions can, again, help make sure that the right treatment is delivered to the right patients at the right time. They also contribute to the search for novel drugs.
In some ways, the third genome – that of the vector – is considered the most intractable. 'Studying mosquito genomics is difficult because their genomes are so diverse', adds Kwiatkowski. 'You will typically find five million base differences between the maternal and paternal genomes of an individual mosquito, and this level of diversity makes genome assembly in these species one of the most complex current problems in all computational genomics'. It is, at least, a task that can benefit from economies of scale: all mosquito genome sequences, like parasite and patient sequences, are uploaded to the cloud where they can be compared to the complete global dataset.
It is self-evident that infectious diseases respect no boundaries. If epidemic outbreaks and endemic diseases are to be monitored successfully, let alone controlled, scientists and clinicians must cross boundaries too: between disciplines as well as between nations. The emerging science of computational molecular epidemiology already has a major part to play.
