Technology transfer means an astonishing number of things to different people, in almost as many contexts – from large scale international cooperation programmes through internal corporate dispersion of methodologies to local reusability of information. Underpinning it all, regardless of scale or purpose, are data analytic needs/benefit assessments – data analysis, or data itself, may often be the technology to be transferred.
Perhaps the most widely familiar current case is strategic transfer of industrial technologies in pursuit of commercial or foreign policy objectives. Export of ‘cleaner’ (lower CO2 emission) energy generation methods into developing economies is probably top of the bill here, though providing low-cost nuclear facilities as a disincentive to proliferative development of local expertise runs close behind.
Less dramatically visible, but perhaps just as significant and far reaching, is the transfer of information and communication technologies (including scientific computing manifestations) which can, and does, happen rapidly at all levels from the governmental to the informal. Transformation of many developing economies by arrival not only of such technologies, but of the thinking and approaches that accompany them, can be profound, unpredictable and uneven. Chatting about events in the mountain village from which she comes, a Pakistani colleague mentions in the same sentence GPS micromanaged agriculture and vendetta killings planned using a well-known data analysis product. In the seas off Somalia, both foreign seismologists and local pirates use the same data analysis product in conjunction with satellite communications to inform their very different professional practices.
Transfer may also be across areas within a particular field of study or endeavour, or geographical area, or both, as for example in the Great Basin restoration initiative. Across several US states, this initiative transfers the outcomes of specific studies (such as yield responses of invasive grasses to carbon doses[1]) into larger ecological intervention processes.
Throughout scientific computing, the transfer of technologies (regardless of scale) presupposes continued access to data, metadata and models generated during progressive development cycles. These data must be transferred continually up the often steep gradient of technical development. The rate of obsolescence in storage over the first 50 or 60 years was, in retrospect, frightening, and accelerated further with the advent of mass market desktop machines. In the 14 years of Scientific Computing World’s life, my backup stores have been migrated across five generations of media – and I know of potentially valuable data from the beginning of that time which remains, effectively lost, on 5.25-inch floppies.
The arrival of large and cheap hard disks, combined with general availability of high speed communications, has encouraged dispersed storage and widespread data sharing habits, moderating that problem of physical access to a considerable extent. Software access, however, continues to be an issue. I was recently presented[2] with the only copy in the world of a large and detailed longitudinal epidemiology data set, backed up onto VHS video cassettes. Ignored for 20 years, it was suddenly relevant to a new methodological context and new beneficiary groups. Copied onto a network where it would be safe, decoded using software supplied by an Albanian hobbyist, the data had finally to be extracted from obsolete files generated by Wingz. Wingz was a ground-breaking spreadsheet program in its day, ahead of the competition and its time, but last seen in the year of SCW’s birth. The solution was suggested by a VSNi expert in New Zealand; another decade and it might not have been available.
VSNi’s GenStat has a large repertoire of data format import filters, and an active policy of adding more when they are needed by its users. Given the manic turnover in such formats, as a raw competitive market repeatedly updated the facilities and sophistication which a file had to support, that is a valuable asset that more suppliers should emulate. Researchers and organisations should also plan for the future-proofing of legacy data before the means for reading them fade away. For the future, though, more forethought is needed.
Standards, both planned and de facto, are beginning to evolve for storage and handling. The rise and rise of XML is a prime example, with Oasis Open Document file formats (particularly for ODS spreadsheet components, manifested as the native format in OpenOffice’s Calc) as a specific instance. From a data analysis point of view, the advantages of an open medium such as XML are several. For a start, it provides a possibility of separating data from program vendor, something that has been sorely lacking thus far. To quote Robert Muetzelfedt, honorary fellow at Edinburgh University’s School of Informatics (and a director of Edinburgh spin-off company Simulistics): ‘The real benefit... is when the saved model format is (a) an open, standard format, and (b) designed to be symbolically processable. XML gives you both text (human-readable, non-proprietary) plus access to a variety of tools ... capable of processing the saved model. That’s the key. You then open the door to anyone to make useful tools for processing the model (visualisation, querying, code generation, transformation...), and you suddenly have a revolutionary change in practice.’[3]

A photomicrographic penetration record from Particle Therapeutics is image processed to extract metric data.
Microsoft has, over the past few years, moved from binary formats through proprietary XML to an open XML format compliant with ISO 29500 (a standard published in March 2008). This will not remove the objections to Excel as a data analytic environment, but it will provide more secure access to data stored (as it so often is) in Excel files. Corel, who as publishers of Quattro offer the main proprietary alternative to Excel, has committed to support for both Microsoft and Open Document XML. Both XML formats are published as open specifications, therefore more secure against ‘data lock out’ than their predecessors.
A database file is, in many ways, a better data container than a spreadsheet file, and many analytic products (Statistica and FlexPro, for example) explicitly provide for this, but the XML desktop looks less rosy on that front. Microsoft has stopped short, so far, of an open XML-based native file format for its Access database manager. Import and export in XML do now provide a solution of sorts, but a clunky one that is not going to gain the sort of widespread adoption that spawns standards. Open Office is (unusually) even less accommodating, with formats and settings available as XML, but not the data themselves.
Nevertheless, there is a growing move towards XML databases. Most views of future distributed data sharing environments (internet mediated or otherwise), such as the XDI (extensible resource identifier data exchange) initiative managed by Oasis, are XML-based, large back-end database systems are increasingly supporting XML stores, and XML is the underpinning of several convergence approaches.
In an ideal world, there would be a single database storage format from which spreadsheets, database managers, statistical analyses and the rest could pull data for their own different purposes. An acceptable alternative would be a single, agreed access method for extracting the pure data from multiple formats offering different facilities. We seem to be moving towards a future perched between those options: a small number of formats, perhaps two or three, united by XML and open specifications. The only certain factor, so far, is the role of open standards lobbies (supported by smaller commercial providers and non-commercial pressure groups from the United Nations downwards) in compelling proprietary providers towards data transparency.
Given the inheritance of disparate applications with incompatible formats, interconnection systems such as OLE, ODBC, and so on, provide valuable current connectivity, but no guarantee of permanence. Another approach is to treat an organisation’s information space as a single data universe, facilitating technology transfer within it by buying into a data repository approach that is internally transparent. External transparency is an optional extra, not always considered as a future asset, but since repository information is usually in human readable form harvested from print to file output from the data generating applications it usually follows naturally. Ultimately, the benefit of this in future-proofing terms depends on the chosen storage format, but most such systems allow flexibility in this and, increasingly, put XML on the menu alongside plain text. NuGenesis SDMS is one such scientific data management system, marketed by Waters GmbH (see panel, p14).
Numerical data always represent a loss of information, since they represent only what their generator chose to sample and record, so source preservation is important too. Technology transfer often means applying new techniques to old situations (or, sometimes, old techniques to new situations) and none of us can guarantee that our assessments of what is or is not relevant today will stand the test of time even in the short term. One researcher pointed to the rich seam of apparently ‘cold’ criminal cases opened up for reinvestigation by the transfer into forensic practice of progressively improved DNA testing techniques. Another mourned the volumes of source images shredded by her lab over the years after immediately required metric data had been taken. Preserving source material for remeasurement or resampling can be crucial to subsequent technology transfer efforts, or benefit from them to yield new and unsuspected data.
Particle Therapeutics, in Oxford, do needleless injection. A powdered drug, accelerated to supersonic speeds, directly penetrates the skin. Test firings into a simulation medium, the penetration pattern viewed under a microscope and, in the example shown (see p13), Mathematica image analysis has been used to extract metric data. This is the sort of image that contains far more information than is being extracted for present purposes; like an archaeological site reburied after first survey, if kept it can be reprocessed in different ways for different, perhaps unforeseen, future purposes.
The approach of Dr Norbert Stribeck and colleagues at the University of Hamburg’s Institute of Technical and Macromolecular Chemistry to polymer materials properties analysis points the same way. Here, though, the nature of their work requires that x-ray scattering image, extracted data, and generated artefacts be kept together in a defined relationship. Structures set up in VNI (Visual Numerics) PV-Wave form a task-specified data container within which analyses can be generated and browsed. Since the same environment has been used for 12 years, it also provides a specialised longitudinal data repository. PV-Wave also provides the exploration tools for image processing, computed nanostructure representation, boundary enhancement and time sequence video output.
The word ‘technology’ still tends to bring images of hardware to mind, but increasingly the purely conceptual data, model and process entities are the true embodiment of technologies to be transferred. In areas as diverse as drug discovery and meteorology, the physical manifestation is an expression of entirely virtual prefabrication. Whether they are to be transferred from research to implementation, from generator to user, from field to field, or just from present to future, their preservation and continued accessibility is now one of the principal factors in continued effective scientific progress.
Sources
OASIS, OpenDocument standards, info@oasis-open.org
Particle Therapeutics, Needleless injection systems, info@particletherapeutics.com
University of Hamburg, Polymer materials properties analysis, gd-tmc@chemie.uni-hamburg.de
Visual Numerics, Numerical and visual data, www.vni.com/contact/index.php#InformationRequest
Waters, SDMS, www.waters.com/waters/contactOnline.htm?lset=1&locale=en_GB
Wolfram Research, Mathematica. Finance Essentials package. Mathematica link for Excel. Linkage designer, info@wolfram.co.uk
References
1. Brunson, J.L., Yield responses of invasive grasses to carbon doses. 2008.
2. Grant, F., A fistful of Rosetta stones, in The Growlery. 2008, Blogger.
3. Muetzelfeldt, R., Declarative modelling, to F. Grant. 2006, Unpublished correspondence: Edinburgh.
Dr Maren Fiege, Waters GmbH
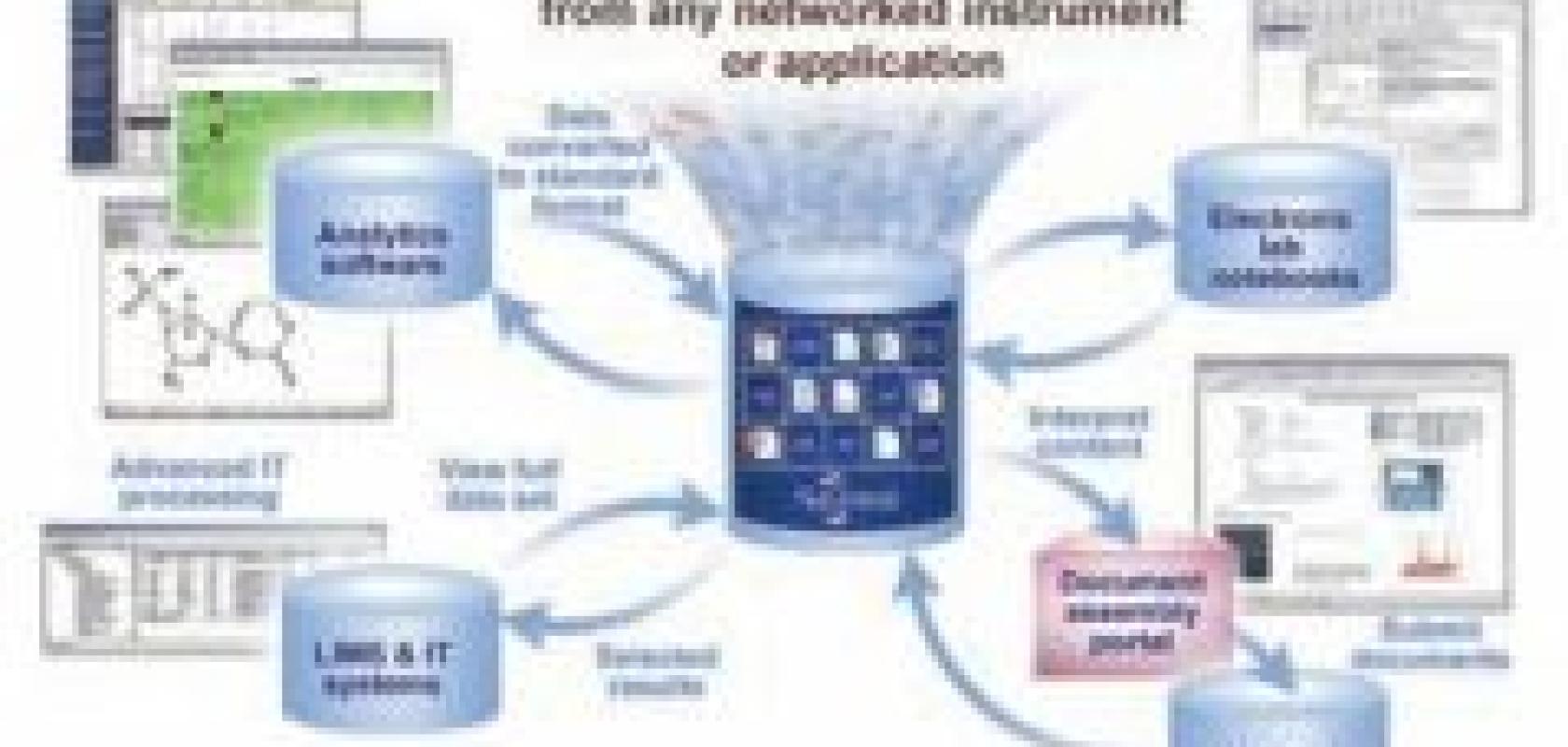
Scientists today utilise a multitude of different instruments and applications producing large amounts of data in different formats, and analytical result reports often form the basis of subsequent statistical and data analysis. Organising and repurposing this data for further analysis can be challenging: structure may differ widely from instrument-to-instrument and a suitable conversion interface may not be available. To transcribe or reformat the data manually is tedious, time-consuming, and error prone. Standardised data repurposing improves efficiency, reduces errors, and supports regulatory compliance.
Capturing and cataloguing analytical data from different analytical instruments into a centralised electronic repository represents the first step in standardised data reformatting and repurposing. Modern data management systems capture and store result reports in an aggregated, humanreadable, electronically searchable and re-usable format. After aggregation, relevant reports are located, data extracted and reformatted, and analysis carried out.
Such systems capture and automatically catalogue both file-based and print data, allowing users to quickly find information based on metadata as well as content.
Once the required data have been found, a system reads data using extraction templates, which extract and reformat their values into an XML or ASCII standard format that can be easily imported into a data analysis system. Once a template has been configured, it can be applied to multiple reports simultaneously to quickly extract large amounts of data.
An illustration of this approach is a biopharmaceutical company that wanted to automate transfer of ABI Analyst and SoftMax Pro instrumentation data into Excel spreadsheets. Using automated extraction, turnaround time was reduced from 30 minutes per report to one. More than five hours per week was saved, data integrity improved, and 21 CFR Part 11 compliance maintained.
The Doping Control Lab of Karolinska University Hospital in Sweden is another case. Data extraction is used to automatically review TargetLynx MS reports on screening for 140 banned substances per analysed sample. Waters NuGenesis SDMS automatically identifies the positive hits within printed reports, so only these (187 per year as compared to 7,500 previously) need to be analysed in detail. This allows Karolinska to streamline their lab processes and increase sample throughput.
Final data analysis results often require documentation and, again, results captured to the centralised electronic SDMS repository via print-to-database can be repurposed and summarised into final reports.
In summary, automated extraction scientific data management systems help users to harmonise data into a single electronic repository that can be easily searched and re-used, eliminating redundant work and streamlining processes. This repository standardises laboratory processes which enables increased throughput with reduction of cycle times and errors, time spent on further processing, and reduces costs.
