
The rate of change in computer technologies is far greater than in the laboratory and in business, and this unavoidably means that the computing experience in the laboratory will lag behind the consumer experience. Additionally, the constraints of IP, regulatory and legal compliance do not lend themselves to risk-taking when deploying new technologies. New laboratory informatics projects demand a carefully managed and risk-averse approach
Functional/user requirements
Gathering user or functional requirements is one of the key tasks, usually assigned to the project team, to provide a specification against which potential solutions can be evaluated. The task involves uncovering and understanding user-needs, distinguishing them from ‘wants’ and ‘nice to haves’, and aggregating the needs into a requirements specification. In this context, reference to ‘users’ includes not just end-users of the proposed system, but anyone who will interact with the system, or be involved with inputs or outputs to the system. In order to do this, various methods may be used to gather needs and to prioritise them.
The requirements may include, but are not limited to:
- General business requirements;
- User/functional requirements;
- IT requirements;
- Interface requirements;
- Regulatory issues;
- Data management requirements;
- Error handling;
- Reporting requirements; and
- Performance requirements.
The criteria that define required performance may include:
- Access control and security;
- Look and feel;
- Robustness;
- Scalability;
- Ease of use;
- Technical performance/response times; and
- Technical support.
All of these requirements are normally collated into a request for proposal (RFP) that will be submitted to potential vendors. The RFP should also provide more general information, including an introductory description of the organisation and the major objectives of the project, as well as diagrams showing relevant workflows. The RFP may be preceded by a request for information (RFI) – a means of gathering information about a potential vendor’s products and services, which may be used to fine-tune a final list of vendors to whom the RFP may be submitted.
Unfortunately, users are notoriously bad at stating what they need. Most systems are specified or designed by a team or committee and the team/committee members tend to be volunteers who are committed to the concept of the system, enthused about the improvements it can bring, and are able to envision the potential. Unfortunately, the committee process can create complex systems and reflect compromises, and it is often the case that most problems come from people who don’t volunteer for the committee! By definition, the members of the team are more committed to the success of the project than those who are not directly involved. In their deliberations, project teams often develop a concept of a solution that is much more sophisticated than might be needed or, indeed, is economically justifiable.
Typically the requirement-gathering phase involves harvesting needs, wants and ideas from the potential user community, and then engaging in a prioritisation exercise to reduce the list to a specific set of requirements that form the basis of a request for proposal (RPF) to be presented to vendors.
It is important that the business requirements are fully clarified first of all; this ensures that the scope of the project is defined and can therefore help exclude some of the more exotic ‘needs’ that might arise. Any single item on the requirements list should justify itself not only financially, but also in terms of its usefulness and ease of use.
Anecdotal experience suggests that some requirements specifications could be shrunk by between 25 and 50 per cent by the removal of ‘wish list’ items – bringing cost-savings and lower cost of ownership, as well as easier user adoption. It is important for the project team and sponsors to be able to define what business problem the electronic laboratory notebook (ELN) will solve, and to ensure that user requirements are kept simple and are focused on solving the problem.
The formal RFI and RFP approaches can only go so far, and it is essential that candidate systems be demonstrated and assessed with some preliminary configuration to establish and evaluate not only whether the system meets the functional requirements, but also whether it provides an acceptable user experience. In some respects, it makes sense to consider functional requirements and user requirements as separate criteria.
Business case development and project management
Building a good business case requires a thorough and systematic approach to understanding current limitations as well as future requirements for the business. It is important to see laboratory informatics as a component in a laboratory ecosystem (technology, processes and people), rather than ‘just another laboratory application’. The following points should all be considered in formulating the case for a new informatics system.
Why do we need a new system?
- What is the problem that needs to be solved?
- Is there any quantitative data that illustrates the problem?
- Which laboratory areas will be involved in the project?
- Who makes the go/no-go decision?
- What are the issues relating to IP (internal/legal/patent)? and
- Are there any regulatory compliance requirements?
Clarify why the organisation thinks it needs a new system. This is best achieved by developing a problem statement that quantifies a specific problem, or set of problems, about the laboratory’s productivity and/or knowledge management performance.
The scope and scale of the problem (and hence, the solution) should be identified. The key decision-makers/budget-holders should also be identified, plus any other interested party who may have influence over a go/no-go decision. It is important to know what business level constraints may apply in terms of internal, legal or regulatory compliance.
Laboratory/company background
- Use organisation charts to clarify roles and responsibilities and organisational relationships;
- Identify the nature and scientific disciplines of the laboratory work and how they relate to each other; and
- Establish whether outsourced agencies (contract labs) are involved?
Establish the way in which the laboratory is organised, the nature of the work it undertakes and how it relates to internal and external organisations with whom it collaborates.
Current laboratory processes and systems
- Which laboratory systems are already in use?
- (Are there SOPs?)
- Which data acquisition systems are already in use?
- Which teamwork/collaboration systems are already in use?
- Which document management systems are already in use?
- Who is responsible for the management and support of these systems?
- Is there a (electronic) records management policy? and
- Are there any specific policies an restraints relating to the introduction of ITsystems?
Establish how the laboratory is currently working, paying specific attention to the use and effectiveness of manual systems such as worksheets, paper lab notebooks, and data management. Also identify major ‘electronic’ systems used for the acquisition, processing and management of data, and ask what happens to this data – where is it stored and for how long? Is it communicated or transferred elsewhere – if so, how? Is it backed up and/or archived? Can it be found?
Is laboratory data the responsibility of the laboratory, or does IT have any involvement? What level of involvement does IT have in the purchase and implementation of laboratory systems?
Future laboratory processes and systems
- Based on interviews with laboratory managers and laboratory staff, a model should be developed to illustrate the major relationships between laboratory data and information;
- Construct data workflow and laboratory process diagrams;
- Identify any conflicts in nomenclature and establish an agreed taxonomy;
- Identify the role (scope and scale) of existing laboratory systems in the model and diagrams; and
- Test the model and diagrams against each of the laboratory areas and other interested parties (IT, legal, QA, records management).
A high-level plan, showing the relationships, processes and data flows that describe a future state for the laboratory, should be developed. This should include an identified role for each of the laboratory systems and should clarify the specific functions of each. Any problems with laboratory terminology should be resolved. The plan should be tested by presentation and discussion with the interested parties.
Business plan development
- Quantify the benefits of the proposal, in particular productivity gains, ROI and knowledge management, and support these estimates with case studies;
- Undertake a risk assessment, paying attention to process, technology and people-related risks. Align the risk assessment to the set of user requirements; and
- Prepare, and include in the business case, a high-level implementation plan that addresses any specific requirements and/or risks that have been identified.
Quantitative benefits should be identified, along with all risks. An implementation plan should address known risks and/or potential problems, in particular the strategic approach to roll out, e.g. a progressive deployment, the composition of the project team, change management and user support.
Human factors
- What practical problems do laboratory workers experience with existing laboratory processes and data workflows?
- How well will laboratory workers accommodate change? and
- Are there any cultural, political or other internal relationships that could have an impact on the project?
Potential problems associated with change management show be identified. This may be at an individual level or at an organisational level.
Internal culture and technology adoption
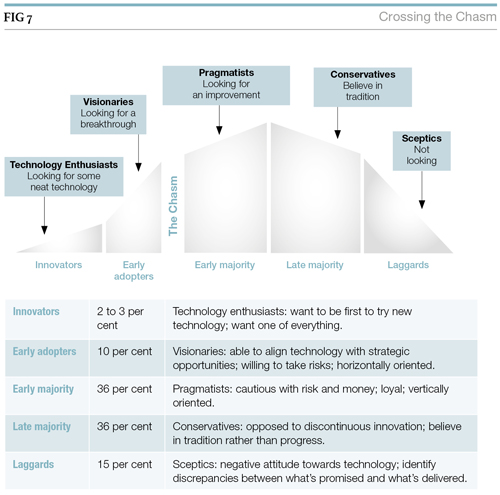
The introduction of multi-user IT systems into organisations has a mixed track record. Multi-user systems are usually specified by a project team and often contain a number of compromises and assumptions about the way people work. High-level business objectives can therefore be put in jeopardy if users do not successfully adopt the new system. However, most case studies on electronic laboratory notebook implementations indicate a positive user take-up. This may be attributed to a growing understanding of aspects of technology adoption, originally reported by Everett Rogers in his book, The Diffusion of Innovations,[15] and developed further by Geoffrey Moore in Crossing the Chasm[16]. Moore’s ‘Chasm’ (see Figure 7) is the gap between the early adopters and the mainstream market. The early adopters are a relatively easy market. Targeting them initially is important, but the next phase of the marketing strategy must target the conservative and pragmatic majority. The early adopters can play a central role in this. Since the electronic laboratory notebook (ELN) project team is likely to be formed from the early adopters, they can play a pivotal role not only in specifying and selecting a solution, but in articulating the rationale for the ELN, provide training and ongoing support to the conservative and pragmatic majority.
User adoption is often considered one of the most critical success factors of an IT project, and paying appropriate attention to user requirements will enhance the likelihood of success. Key to this is the recognition that people are more likely to comply with a request when:
- A reason is provided;
- There is give and take;
- They see others complying;
- The request comes from someone they respect or like; and
- The request comes from a legitimate source of authority.
Concerns about user adoption can be reduced by carefully choosing the project team to ensure that these criteria are addressed, rather than just announcing a new system and the training course schedule. Typically, putting a strong emphasis on user requirements and user adoption by engaging users throughout the process tends to brand the implementation as a ‘laboratory’ project, rather than an ‘IT’ project, and this can make it easier for scientists to accept the proposed change.
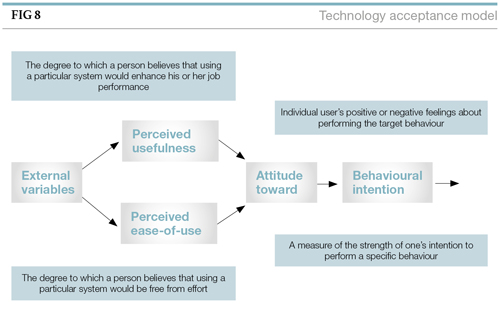
The Technology Acceptance Model[17] (see Figure 8) is an information systems theory that models how users come to accept and use a technology. The model suggests that, when users are presented with a new software package, a number of factors influence their decision about how and when they use it. The main ones are:
- Perceived usefulness (PU): ‘The degree to which a person believes that using a particular system would enhance his or her job performance’; and
- Perceived ease-of-use (EOU): ‘The degree to which a person believes that using a particular system would be free from effort.’
The technology acceptance model assumes that, when someone forms an intention to act, they will be free to act without limitation. In the real world there will be many constraints such as limited ability, time constraints, environmental or organisational limits, or unconscious habits that will limit the freedom to act.
Concentration on the positive aspects of ‘usefulness’, both to the organisation and to the individual, and ‘ease of use’ will help users develop a positive attitude. It is in this area that the early adopters can have a powerful influence on their conservative and pragmatic peers.
Technology considerations
Multi-user informatics systems are typically based on two- or three-tiered structures in which the application software and database may share a server or be located on separate servers, and the client-side software deployed on a local desktop, laptop or mobile device. Traditionally, the servers are based in-house, but hosted services (cloud/SaaS) are generating increasing interest, based on potential business benefits.
From the user perspective, the client-side options fall into two categories: thick client and thin client. The thick client is usually a substantial software installation on a local computer in which a good deal of the data processing is undertaken before passing the output to the database server. This has the advantage of distributing the total processing load over a number of clients, rather than the server, and may also allow a certain amount of personalisation of the client software to support individual users’ needs.
The downside is that system upgrades can become time-consuming and potentially troublesome, depending on the local configuration – although centrally managed systems are now making thick client systems easier to deploy, maintain and support.
Thin clients typically access the application and database server(s) through a browser. No local processing power is used, so the server and network performance are critical factors in providing good performance. The use of a browser can significantly reduce deployment and upgrade costs, but may restrict or limit user configurability.
With regard to devices, successful deployments have been made with:
- Small form-factor PCs on the laboratory bench;
- ‘Remote desktop’;
- Citrix; and
- A KVM switch operating between a desk-bound processor unit with keyboards and screens on the desk and in the laboratory.
There is a growing level of interest in how consumer technologies can enhance the user experience of working with laboratory informatics tools. With their focus on sharing, collaboration, interaction and ready access to information, consumer technologies exhibit considerable synergy with the high-level criteria associated with current business requirements. Primarily, these focus on ‘mobile’ (portable devices), ‘cloud’ (access from anywhere), ‘Big Data’ (the need to be able to access and interpret vast collections of data) and ‘social’ (collaborative tools).
The big attraction of mobile devices for end users is portability. A common complaint in the transition from paper systems to electronic is the loss of portability of, for example, a paper lab notebook.
The form factor of a laptop computer goes part way to resolving this concern, but the emergence of compact, lightweight tablets holds far more potential. Although tablets are often considered to be ‘data consumers’ – great for reviewing data but less effective for data entry – careful design of the user interface can optimise their potential for narrow, dedicated functions.
Typically, mobile devices offer significant potential for accessing data from remote locations, or for capturing certain types of data in the field. The user experience can be enhanced by the use of mobile devices that feature simple, gesture-based interactions for on-screen navigation, consistent with typical consumer applications. Furthermore, the adoption of web technologies creates the opportunity to design a platform that supports all types of end-user devices, making critical laboratory data available anytime, anywhere, on any device in a global wireless and mobile environment.
The adoption of mobile devices for informatics-based tasks raises a further question about how the host system is deployed and, in particular, how the mobile device communicates with the host. Synchronisation is one option, which has the advantage of not requiring remote connectivity, but it means that data must be held locally on the device. Wireless connectivity to a hosted system (SaaS or cloud) has the benefit of direct access to the system.
From a business perspective, the cloud offers an effective solution to the increasing demand for the implementation of collaboration tools across multiple departments, multiple sites and different geographies – including outsourced operations where the practicalities of deployment are largely limited to configuration rather than physical installation of hardware and software. The benefits of a thin client – access from anywhere, low start-up costs and centralised support – has both financial and functional attractions.
Pitted against this are concerns about access control, security, and data integrity.
Some informatics vendors already offer this type of service. Cloud services generally fall into one of two categories: public clouds and private clouds. Public clouds utilise a single code base for the service to multiple clients. The single code base limits customisation and integration, but helps keep costs down. A private cloud will typically offer a code base specific to an individual client, and will accommodate customisation and integration, but will normally come at a higher management cost.
Chapter summary
The purchase and implementation of a laboratory informatics system represents a major cost to the laboratory. It also represents the start of a relatively long-term relationship with the vendor. Deploying a new system changes the working lives of laboratory workers and, as is the case with any significant change, planning takes on a critical role in the process.
Next: Knowledge: Data analytics >
